Table of Contents
Parse no more—the wire format is the memory format.
Official Documentation (with examples): lite3.io
Read more about the design of Lite³
Introduction
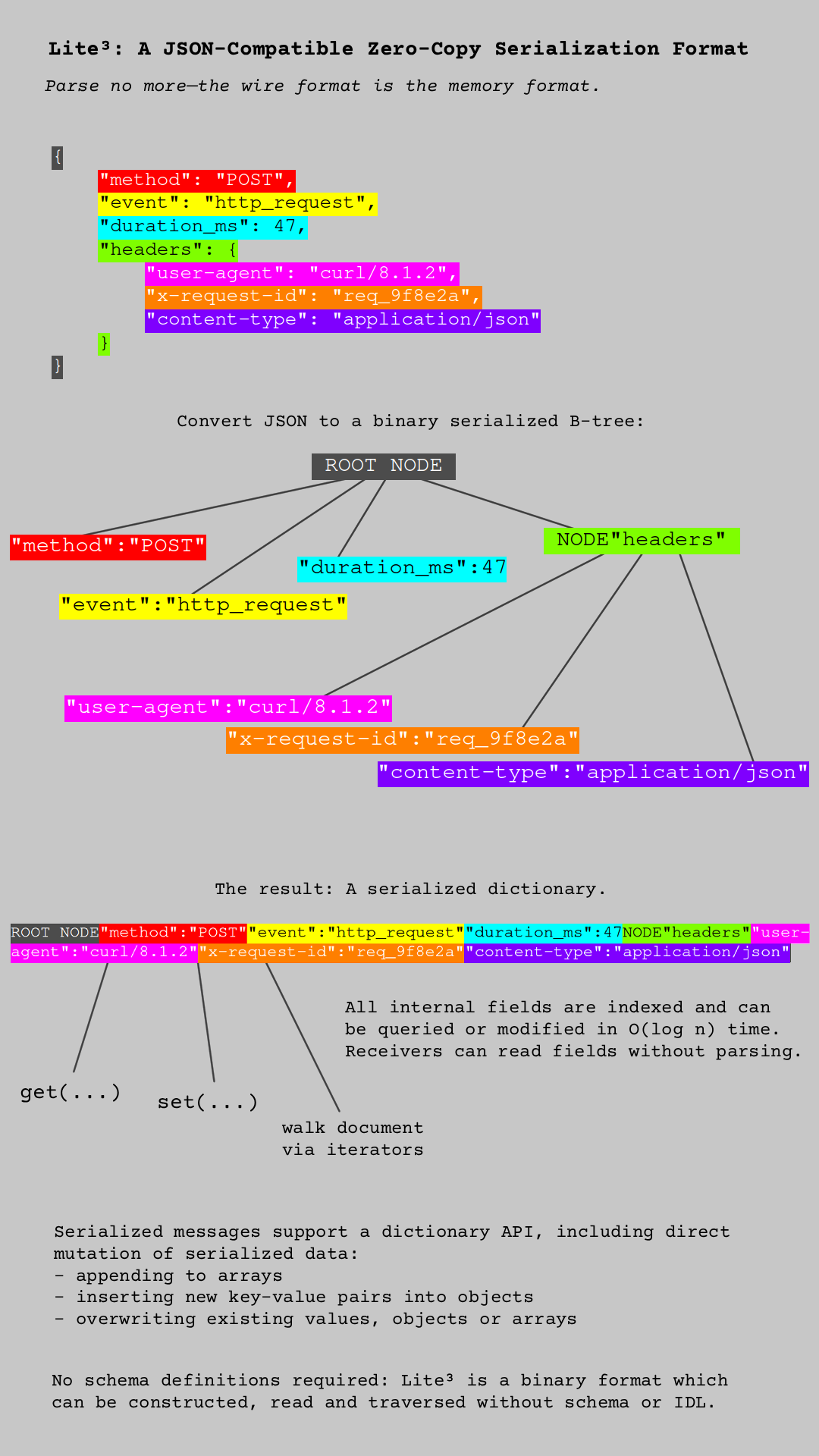
Lite³ is a zero-copy binary serialization format encoding data as a B-tree inside a single contiguous buffer, allowing access and mutation on any arbitrary field in O(log n) time. Essentially, it functions as a serialized dictionary.
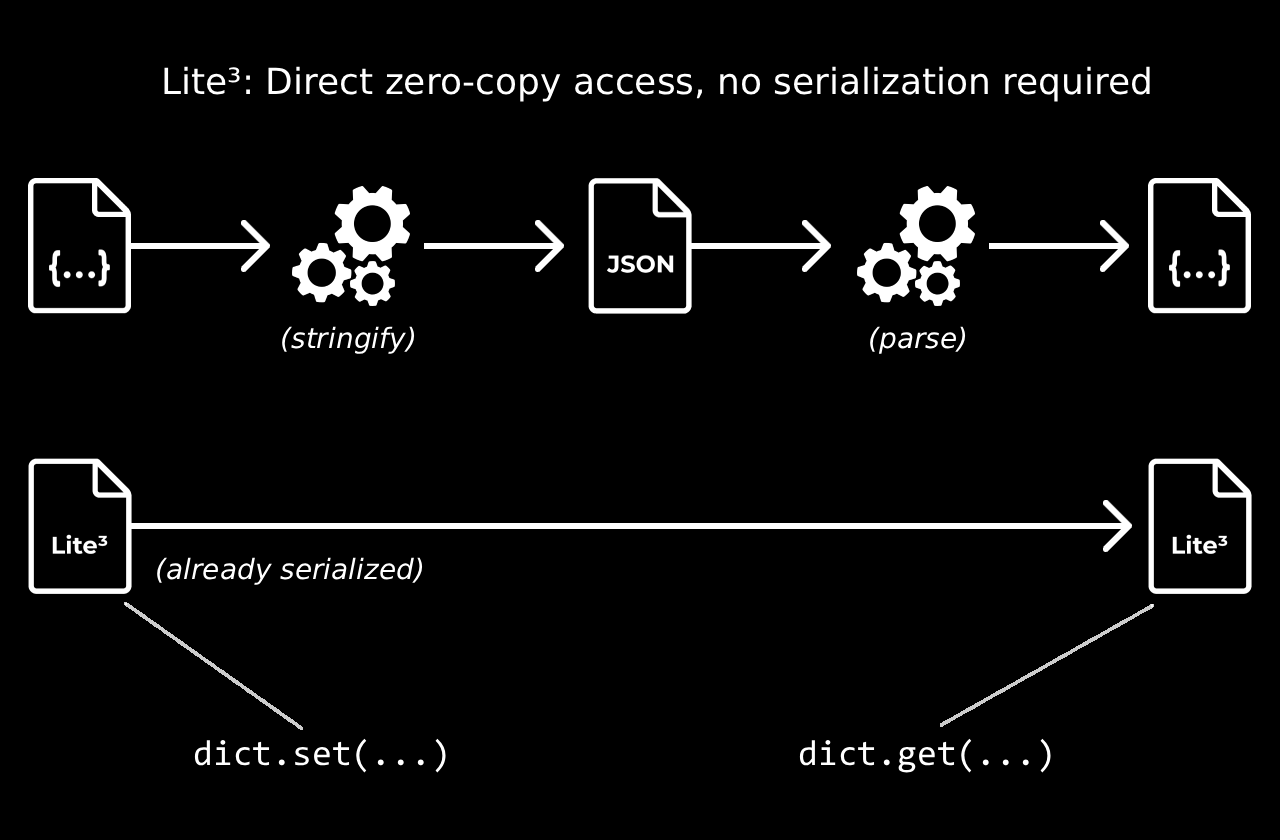
As a result, the serialization boundary has been broken: 'parsing' or 'serializing' in the traditional sense is no longer necessary. Lite³ structures can be read and mutated directly similar to hashmaps or binary trees, and since they exist in a single contiguous buffer, they always remain ready to send.
Compared to other binary formats, Lite³ is schemaless, self-describing (no IDL or schema definitions required) and supports conversion to/from JSON, enabling compatibility with existing datasets/APIs and allowing for easy debugging/inspecting of messages.
Thanks to the cache-friendly properties of the B-tree and the very minimalistic C implementation (9.3 kB), Lite³ outperforms the fastest JSON libraries (that make use of SIMD) by up to 120x depending on the benchmark. It also outperforms schema-only formats, such as Google Flatbuffers (242x). Lite³ is possibly the fastest schemaless data format in the world.
Example to illustrate:
- A Lite³ message is received from a socket
- Without doing any parsing, the user can immediately:
- Lookup keys and read values via zero-copy pointers
- Insert/overwrite arbitrary key/value entries
- After all operations are done, the structure can be transmitted 'as-is' (no serialization required, just
memcpy()) - The receiver then has access to all the same operations
Typically, in such a scenario a distinct 'serializing' and 'deserializing' step would be required. However Lite³ blurs the line between memory and wire formats, allowing direct access, traversal and mutation of a serialized buffer.
Features
- Schemaless & self-describing, no IDL or schema definitions required
- Zero-copy reads + writes of any data size
- Lives on OSI layer 6 (transport/protocol agnostic)
- O(log n) amortized time complexity for all IOPS
- Built-in pointer validation
- Low memory profile
- Predictable latency
- No
malloc()API, caller provides buffer - Library size 9.3 kB (core) and dependency-free
- Written in C11 using GNU C syntax
- Optional subdependency (yyjson) to support conversion to/from JSON
- MIT license
Code Example
Lite³ is a binary format, but the examples print message data as JSON to stdout for better readability.
Here is an example with error handling omitted for brevity, taken from examples/buffer_api/01-building-messages.c:
Output:
Lite³ provides an alternative API called the 'Context API' where memory management is abstracted away from the user.
This example is taken from examples/context_api/04-nesting.c. Again, with error handling omitted for brevity:
Output:
For a complete How-to Guide with examples, see the documentation.
Getting Started
Make Commands
| Command | Description |
|---|---|
make all | Build the static library with -O2 optimizations (default) |
make tests | Build and run all tests |
make examples | Build all examples |
make install | Install library in /usr/local (for pkg-config) |
make uninstall | Uninstall library |
make clean | Remove all build artifacts |
make help | Show this help message |
Installation
A gcc or clang compiler is required due to the use of various builtins.
First clone the repository:
Then choose between installation via pkg-config or manual linking.
Installation via pkg-config (easiest)
Inside the project root, run:
This will build the static library, then install it to /usr/local and refresh the pkg-config cache. If installation was successful, you should be able to check the library version like so:
You can now compile using these flags:
For example, to compile a single file main.c:
Installation via manual linking
First build the library inside project root:
Then in your main program:
- Link against
build/liblite3.a - And include:
include/lite3.h+include/lite3_context_api.h
For example, to compile a single file main.c:
Using the library
Choose your API
The Buffer API provides the most control, utilizing caller-supplied buffers to support environments with custom allocation patterns, avoiding the use of malloc().
The Context API is a wrapper around the Buffer API where memory allocations are hidden from the user, presenting a more accessible interface. If you are using Lite³ for the first time, it is recommended to start with the Context API.
There is no need to include both headers, only the API you intend to use.
Library error messages
By default, library error messages are disabled. However it is recommended to enable them to receive feedback during development. To do this, either:
- uncomment the line
// #define LITE3_ERROR_MESSAGESinside the header file:include/lite3.h - build the library using compilation flag
-DLITE3_ERROR_MESSAGES
If you installed using pkg-config, you may need to reinstall the library to apply the changes. To do this, run:
Building Examples
Examples can be found in separate directories for each API:
examples/buffer_api/*examples/context_api/*
To build the examples, inside the project root run:
To run an example:
For learning how to use Lite³, it is recommended to follow the How-to Guide series.
Feature Matrix
| Format name | Schemaless | Zero-copy reads[^1] | Zero-copy writes[^2] | Human-readable[^3] |
|---|---|---|---|---|
| Lite³ | ✅ | ✅ O(log n) | ✅ O(log n) | ⚠️ (convertable to JSON) |
| JSON | ✅ | ❌ | ❌ | ✅ |
| BSON | ✅ | ❌ | ❌ | ⚠️ (convertable to JSON) |
| MessagePack | ✅ | ❌ | ❌ | ⚠️ (convertable to JSON) |
| CBOR | ✅ | ❌ | ❌ | ⚠️ (convertable to JSON) |
| Smile | ✅ | ❌ | ❌ | ⚠️ (convertable to JSON) |
| Ion (Amazon) | ✅ | ❌ | ❌ | ⚠️ (convertable to JSON) |
| Protobuf (Google) | ❌ | ❌ | ❌ | ❌[^4] |
| Apache Arrow (based on Flatb.) | ❌ | ✅ O(1) | ❌ (immutable) | ❌ |
| Flatbuffers (Google) | ❌ | ✅ O(1) | ❌ (immutable) | ❌ |
| Flexbuffers (Google) | ✅ | ✅[^5] | ❌ (immutable) | ⚠️ (convertable to JSON) |
| Cap'n Proto (Cloudflare) | ❌ | ✅ O(1) | ⚠️ (in-place only) | ❌ |
| Thrift (Facebook) | ❌ | ❌ | ❌ | ❌ |
| Avro (Apache) | ❌ | ❌ | ❌ | ❌ |
| Bond (Microsoft, discontinued) | ❌ | ⚠️ (limited) | ❌ | ❌ |
| DER (ASN.1) | ❌ | ⚠️ (limited) | ❌ | ❌ |
| SBE | ❌ | ✅ O(1) | ⚠️ (in-place only) | ❌ |
[^1]: Zero-copy reads: The ability to perform arbitrary lookups inside the structure without deserializing or parsing it first. [^2]: Zero-copy writes: The ability to perform arbitrary mutations inside the structure without deserializing or parsing it first. [^3]: To be considered human-readable, all necessary information must be provided in-band (no outside schema). [^4]: Protobuf can optionally send messages in 'ProtoJSON' format for debugging, but in production systems they are still sent as binary and not inspectable without schema. Other binary formats also support similar features, however we do not consider these formats 'human-readable' since they rely on out-of-band information. [^5]: Flexbuffer access to scalars and vectors is O(1) (ints, floats, etc.). For maps, access is O(log n).
Remember that we judge the behavior of formats by their implementation rather than by their official spec. This is because we cannot judge the behavior of hypothetical non-existent implementations.
Benchmarks
Simdjson Twitter API Data Benchmark
This benchmark by the authors of the official simdjson repository was created to compare JSON parsing performance for different C/C++ libraries.
An input dataset twitter.json is used, consisting ~632 kB of real twitter API data to perform a number of tasks, each having its own category:
- top_tweet: Find the tweet with the most number of retweets.
- partial_tweets: Iterate over all tweets, extracting only a number of fields and storing it inside an
std::vector. - find_tweet: Find a tweet inside the dataset with a specific ID.
- distinct_user_id: Collect all unique user IDs inside the dataset and store it inside an
std::vector<uint64_t>.
While these tasks are intended to compare JSON parsing performance, they represent real patterns inside applications in which data might be queried.
Text formats do not contain enough information for a parser to know the structure of the document immediately. This structure must be 'discovered' by finding brackets, commas, semicolons etc. Through this process, the parser acquires information necessary for traversal. An unfortunate result of this, is that typically the entire dataset must be fed through the CPU, even if a query is only interested in a subset or single field.
A zero-copy format will approach each problem in a different way. It already contains all the information necessary to find internal fields. Only some index structure is required, along with fields of interest. The rest of the dataset is irrelevant to the CPU and might never even enter cache. Therefore to answer a query like 'find tweet by ID', the actual bytes read may be counted only in the hundreds or low thousands out of ~632 kB.
Converting the dataset to Lite³ (a zero-copy format) to answer the exact same queries presents an opportunity to quantify this advantage and reveal something about the cost of text formats.

| Format | top_tweet | partial_tweets | find_tweet | distinct_user_id |
|---|---|---|---|---|
| yyjson | 205426 ns | - | 203147 ns | 207233 ns |
| simdjson On-Demand | 91184 ns | 91090 ns | 53937 ns | 85036 ns |
| simdjson DOM | 147264 ns | 153397 ns | 143567 ns | 150541 ns |
| RapidJSON | 1081987 ns | 1091551 ns | 1075215 ns | 1085541 ns |
| Lite³ Context API | 2285 ns | 17820 ns | 456 ns | 11869 ns |
| Lite³ Buffer API | 2221 ns | 17659 ns | 448 ns | 11699 ns |
To be clear: the other formats are parsing JSON.
Lite³ operates on the same dataset, but converted to binary Lite³ format in order to show the potential.
This benchmark is open source and can be replicated here.
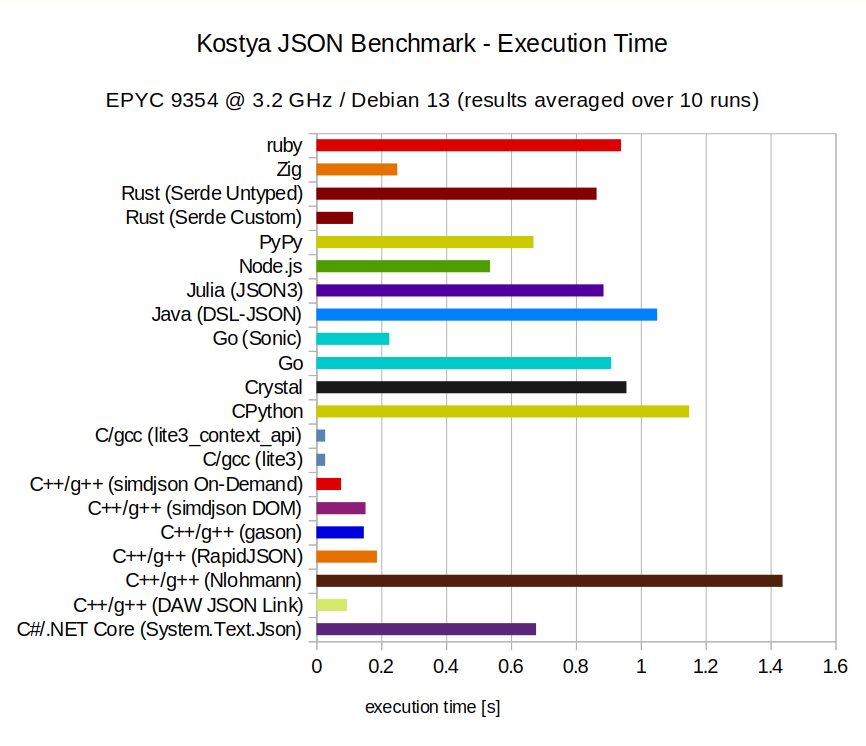
Kostya JSON Benchmark
A somewhat popular benchmark comparing the performance of different programming languages. In the JSON category, a ~115 MB JSON document is generated consisting of many floating point numbers representing coordinates. The program will be timed for how long it takes to sum all the numbers.
The aim for this test is similar: quantifying the advantage of a zero-copy format. This time, reading the entire dataset is unavoidable to produce a correct result. So instead, the emphasis will be on text-to-binary conversion. Because Lite³ stores numbers natively in 64 bits, there is no need to parse and convert ASCII-decimals. This conversion can be tricky for floating point numbers in particular.

| Language / Library | Execution Time | Memory Usage |
|---|---|---|
| C++/g++ (DAW JSON Link) | 0.094 s | 113 MB |
| C++/g++ (RapidJSON) | 0.1866 s | 238 MB |
| C++/g++ (gason) | 0.1462 s | 209 MB |
| C++/g++ (simdjson DOM) | 0.1515 s | 285 MB |
| C++/g++ (simdjson On-Demand) | 0.0759 s | 173 MB |
| C/gcc (lite3) | 0.027 s | 203 MB |
| C/gcc (lite3_context_api) | 0.027 s | 203 MB |
| Go (Sonic) | 0.2246 s | 121 MB |
| Rust (Serde Custom) | 0.113 s | 111 MB |
| Zig | 0.2493 s | 147 MB |
To be clear: the other formats are parsing JSON.
Lite³ operates on the same dataset, but converted to binary Lite³ format in order to show the potential.
This benchmark is open source and can be replicated here.
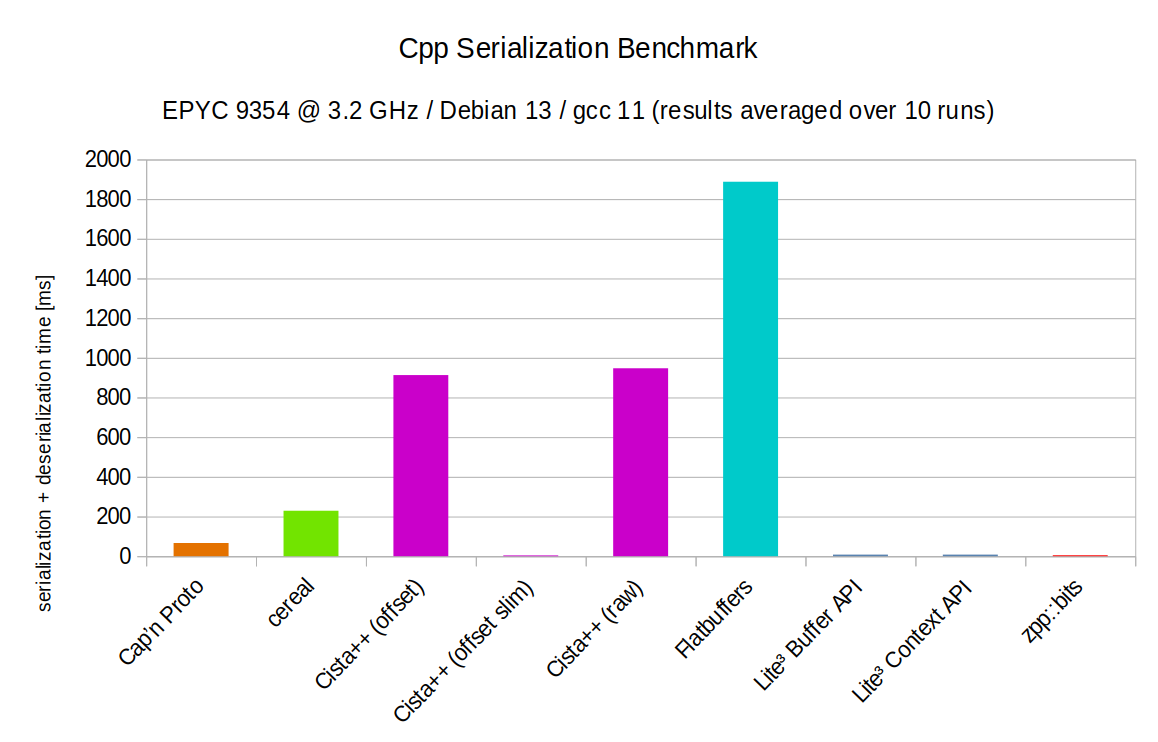
Cpp Serialization Benchmark
It is to be expected that binary formats will perform well compared to text formats. The comparison however is not entirely unwarranted. Pure binary formats present another category, typically requiring schema files and extra tooling. They are chosen by those who value performance over other considerations. In doing so, trade-offs are made in usability and flexibility.
Lite³ also being a binary format, rather opts for a schemaless design. This produces a more balanced set of trade-offs with the notable feature of JSON-compatibility.
Performance of course will remain a strong selling point. This next benchmark originates from the Cista++ serialization library to compare several binary formats, including zero-copy formats. The measurements cover the time required to serialize, deserialize and traverse a graph consisting of nodes and edges. The Cista++ authors created three variants for their format, notably the 'offset' and 'offset slim' variants where the edges use indices to reference nodes instead of pointers.
| Name | Serialize + Deserialize | Deserialize | Serialize | Traverse | Deserialize and traverse | Message size |
|---|---|---|---|---|---|---|
| Cap’n Proto | 66.55 ms | 0 ms | 66.55 ms | 210.1 ms | 211 ms | 50.5093 MB |
| cereal | 229.16 ms | 98.76 ms | 130.4 ms | 79.17 ms | 180.7 ms | 37.829 MB |
| Cista++ (offset) | 913.2 ms | 274.1 ms | 639.1 ms | 79.59 ms | 80.02 ms | 176.378 MB |
| Cista++ (offset slim) | 3.96 ms | 0.17 ms | 3.79 ms | 79.99 ms | 80.46 ms | 25.317 MB |
| Cista++ (raw) | 947.4 ms | 289.2 ms | 658.2 ms | 81.53 ms | 113.3 ms | 176.378 MB |
| Flatbuffers | 1887.49 ms | 41.69 ms | 1845.8 ms | 90.53 ms | 90.35 ms | 62.998 MB |
| Lite³ Buffer API | 7.79 ms | 4.77 ms | 3.02 ms | 79.39 ms | 84.92 ms | 38.069 MB |
| Lite³ Context API | 7.8 ms | 4.76 ms | 3.04 ms | 79.59 ms | 84.13 ms | 38.069 MB |
| zpp::bits | 4.66 ms | 1.9 ms | 2.76 ms | 78.66 ms | 81.21 ms | 37.8066 MB |
This benchmark is open source and can be replicated here.
Security
Lite³ is designed to handle untrusted messages. Being a pointer chasing format, special attention is paid to security. Some measures include:
- Pointer dereferences preceded by overflow-protected bounds checks.
- Runtime type safety.
- Max recursion limits.
- Generational pointer macro to prevent dangling pointers into Lite³ buffers.
If you suspect to have found a security vulnerability, please contact the developer.
Q&A
Q: Should I use this instead of JSON in my favorite programming language?
A: If you care about performance and can directly interface with C code, then go ahead. If not, wait for better language bindings.
Q: Should I use this instead of Protocol Buffers (or any other binary format)?
A: In terms of encode/decode performance, Lite³ outperforms Protobuf due to the zero-copy advantage. But Lite³ must encode field names to be self-describing, so messages take up more space over the wire. So choose Lite³ if you are CPU-constrained. Are you bandwidth constrained? Then choose Protocol Buffers and be prepared to accept extra tooling, IDL and ABI-breaking evolution to minimize message size.
Q: Can I use this in production?
A: The format is developed for use in the field, though keep in mind this is a new project and the API is unstable. Also: understand the limitations. Experiment first and decide if it suits your needs.
Q: Can I use this in embedded / ARM?
A: Yes, but your platform should support the int64_t type, 8-byte doubles and a suitable C11 gcc/clang compiler, though downgrading to C99 is possible by removing all static assertions. The format has not yet been tested on ARM.
Roadmap
- [ ] Optimize build and add support for
-flto - [ ] Built-in defragmentation with GC-index
- [x] Full JSON interoperability with arrays & nested objects
- [x] Opt-out compilation flag for
yyjson - [x] Handling key collisions
- [ ] Size benchmark for compression ratios using different codecs
- [ ] Add language bindings
- [ ] Write formal spec
Mailing List
If you would like to be part of developer discussions with the project author, consider joining the mailing list:
devlist@fastserial.com
To join, send a mail to devlist-subscribe@fastserial.com with non-empty subject. You will receive an email with instructions to confirm your subscription.
Reply is set to the entire list, though with moderation enabled.
To quit the mailing list, simply mail devlist-unsubscribe@fastserial.com
Credit
This project was inspired by a paper published in 2024 as Lite²:
Tianyi Chen †, Xiaotong Guan †, Shi Shuai †, Cuiting Huang † and Michal Aibin †
(2024).
Lite²: A Schemaless Zero-Copy Serialization Format
https://doi.org/10.3390/computers13040089
A serialization format is described where all entries are organized as key-value pairs inside of a B-tree. The paper authors got their idea from SQL databases. They noticed how it is possible to insert arbitrary keys, therefore being schemaless. Also, performing a key lookup can be done without loading the entire DB in memory, thus being zero-copy.
They theorized that it would be possible to remove all the overhead associated with a full-fledged database system, such that it would be lightweight enough to be used as a serialization format. They chose the name Lite² since their format is lighter than SQLite.
Despite showing benchmarks, the paper authors did not include code artifacts.
The Lite³ project is an independent interpretation and implementation, with no affiliations or connections to the authors of the original Lite² paper.
The Lite³ name
The name Lite³ was chosen since it is lighter than Lite².
TIP: To type
³on your keyboard on Linux holdCtrl+Shift+Uthen type00B3. On Windows, useAlt+(numpad)0179.
License
Lite³ is released under the MIT License. Refer to the LICENSE file for details.
For JSON conversion, Lite³ also includes yyjson, the fastest JSON library in C. yyjson is written by YaoYuan and also released under the MIT License.